Descrição
Aplicação Web integrada a um banco de dados - Spotify

Construção e implementação de um banco de dados relacional com dados de músicas do spotify para o desenvolvimento de uma aplicação Web utilizando Python, MySQL e Flask.
Analista de Dados Cientista de Dados
Construção e implementação de um banco de dados relacional com dados de músicas do spotify para o desenvolvimento de uma aplicação Web utilizando Python, MySQL e Flask.
O escopo do projeto é dividido em três partes. Primeiramente, são capturados dados via scripts na linguagem python do IBGE e das plataformas Spotify e Spotify Charts. Após obtenção, tratamento e cruzamento dos dados, é então construído, em linguagem MySQL, um banco de dados seguindo uma modelagem dimensional Entidade Relacionamento. Por fim, é criado uma aplicação Web integrada ao banco utilizando as linguagens Python, MySQL, HTML, CSS e JavaScript. Todo o trabalho desenvolvido pode ser encontrado neste repositório.
Com o objetivo de construir um banco de dados com músicas presentes em rankings nacionais do Spotify, a primeira fonte foi o Spotify Charts, um site feito por fãs que apresenta ranking de músicas mais tocadas no Spotify por região ou por gênero, no qual conseguimos dados dos rankings divididos por cidades do Brasil. Com isso, capturou-se microdados das músicas presentes nesses rankings utilizando como fonte API's fornecidas pela Plataforma de Desenvolvimento do Spotify. Por fim, foram capturados, através de uma API disponibilizada pelo IBGE, dados sobre a região de cada cidade que contém ranking para complementar as informações uti.
Foi utilizado um Jupyter Notebook com linguagem Python com a biblioteca Selenium, realizando web scraping, para capturar dados do site Spotify Charts referentes a rankings por semana de cada cidade brasileira presente no site, incluindo os identificadores do Spotify de cada música.
Com esses identificadores, a captação dos microdados das músicas na plataforma Spotify se dá também por Jupyter Notebook com linguagem Python que se comunica com a plataforma via requests às APIs disponibilizadas, passando como parâmetro inicial os identificadores. Dessa fonte, conseguimos diversos atributos das músicas, álbuns e artistas e, desses, foram selecionados os mais relevantes ao projeto para integrar a modelagem.
Os microdados do IBGE também foram obtidos da mesma forma que os do Spotify, via requests à API disponibilizada pelo instituto, capturando os microdados apenas das cidades obtidas do Spotify Charts.
Com todos os dados capturados e salvos em arquivos .CSV, as tabelas são lidas por um Jupyter Notebook com linguagem Python, utilizando a biblioteca pandas, e o cruzamento é feito. Podemos observar a leitura, tratamento e o cruzamento no código abaixo, onde os dados dos rankings retirados do Spotify Charts (df_Charts_Cities) são cruzados com os retirados do Spotify (df_Songs), através do ID da música. Por fim, cruza-se esse resultado com os dados do IBGE (df_Cities), onde a chave utilizada para o cruzamento é o nome da cidade presente nos dados do spotify charts. Nesse último passo foi necessário também uma conferência manual, já que há cidades com nomes iguais.
# Leitura dos dados dos rankings retirados do Spotify Charts via web scraping
url = "https://raw.githubusercontent.com/leticiatavaresds/Banco-de-Dados-Spotify/main/Data/dados_spotify_cidades.csv"
df_Charts_Cities = pd.read_csv(url, index_col=False, delimiter = ',')
df_Charts_Cities.rename(columns={"Track_id": "Song_id"}, inplace= True)
df_Charts_Cities.rename(columns={"City": "Chart"}, inplace= True)
df_Charts_Cities["ID_Chart"] = df_Charts_Cities.Chart.str.lower().str.replace(" ", "_").str.replace("local_pulse", "lp")
df_Charts_Cities["ID_Chart"] = df_Charts_Cities.ID_Chart.str.normalize('NFKD').str.encode('ascii', errors='ignore').str.decode("utf-8")
df_Charts_Cities["Type"]= np.where(df_Charts_Cities['Chart'].str.contains('Local Pulse'), "Local Pulse", "Normal")
df_Charts_Cities["Cidade"] = df_Charts_Cities.Chart.str.replace("Local Pulse ", "")
# Leitura dos dados das músicas obtidos via API do Spotify
url = "https://raw.githubusercontent.com/leticiatavaresds/Banco-de-Dados-Spotify/main/Data/data_songs.csv"
df_Songs = pd.read_csv(url, index_col=False, delimiter = ',')
# Leitura dos dados das cidades obtidos via API do IBGE
url = "https://raw.githubusercontent.com/leticiatavaresds/Banco-de-Dados-Spotify/main/Data/IBGE_cidades.csv"
df_Cities = pd.read_csv(url, index_col=False, delimiter = ',')
# Cruzamento entre os dados do Spotify Charts e do Spotifu utilizando o id da música como chave
df_Charts_Songs = pd.merge(df_Charts_Cities,df_Songs, on = 'Song_id')
# Cruzamento entre a base e os dados do IBGE utilizando a cidade como chave
df_Charts_Songs = pd.merge(df_Charts_Songs,df_Cities[["Cidade", "Código_Cidade"]], on = 'Cidade')
A partir do momento que os dados foram obtidos, entramos na fase da modelagem. Para isso, foi definido as entidades e depois as relações entre elas.
Considerando que a ideia envolvia a recomendação de músicas, a primeira e principal entidade modelada foi a de Música. A ela, então, foi atriuido um ID que a identifica, depois o seu Nome, Duração e Popularidade e, então, as propriedades da música - Explícito, Volume, Dançabilidade, Energia e Valência - que são utilizados no cálculo de recomendação das músicas.
Com a Música criada, chegamos às tabelas de Álbum, com um identificador, nome, data e a imagem da capa; o Artista, com identificador, nome, número de seguidores, popularidade e gêneros musicais e o Ranking, com identificador e a localidade, dividida em Cidade, Estado e Região.
No caso dos gêneros musicais do Artista, primeiro foi pensado modelar como um atributo multivalorado, para que a modelagem apresentasse um atributito desse tipo. Contudo, foi possível adquirir mais de uma imagem por artista e assim o atributo multivalorado Imagem para artista foi criado, o que possibilitou ao gênero ser uma nova entidade com cardinalidade (1,n), já que um gênero só está na nossa base se possui pelo menos um artista o apresenta. Já pensando na presença de um atributo composto, foi utlizado a localidade dos Rankings.
Depois que todas as entidades foram concluídas, foram formadas as relações entre elas. Assim, foi definida a relação Contém entre Ranking e Música, com cardinalidade (1,n) em ambos os lados, pois cada ranking contém pelo menos uma música e nosso banco só contém dados de músicas que estão presentes em pelo menos um ranking, e que possui os atributos Posição (posição da música no ranking) e Data (indicando em qual ranking, separado em semanas, encontra-se uma dada música).
Além disso, temos a relação Tem entre Álbum e Música, onde cada música está em um único álbum, enquanto álbuns podem possuir várias músicas; a relação possui o atributo Faixa, que indica qual a faixa que a música ocupa no álbum. Por fim, temos o elacionamento Performa entre Álbum e Artista, que também possui cardinalidade (1,n) em ambos os lados, já que o álbum pode ser de um mais artistas e nosso banco só contém artista que está relacionado a pelo menos um álbum, podendo ter vários. Abaixo, se encontra a Modelagem Conceitual desenvolvida no programa brModelo.
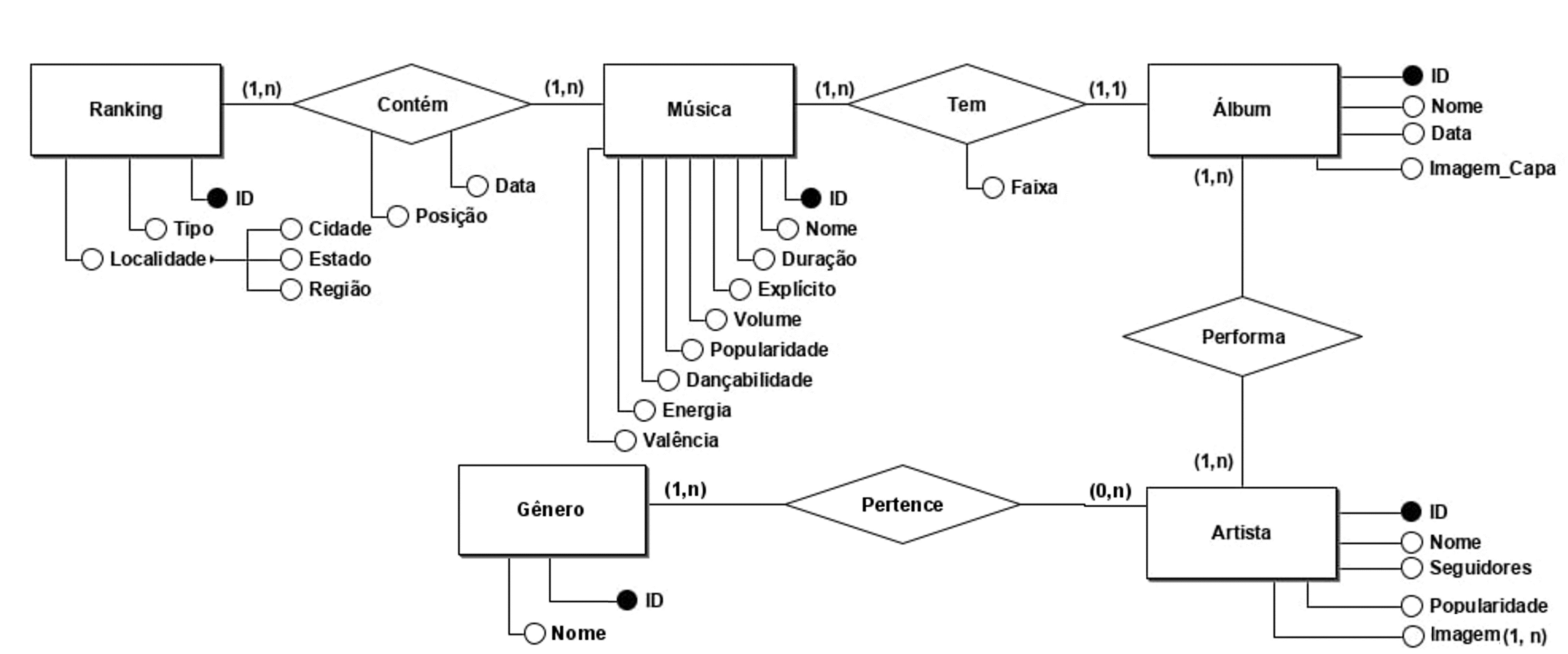
Com a modelagem conceitual concluída, foi usada a função de conversão do brModelo para criar uma versão inicial e, a partir daí, foram tulizadas as regras de conversão para fazer quaisquer modificações necessárias. Neste passo, então, as relações Performa e Contém, além do atributo Gênero de Artista foram transformados em tabelas separadas, utilizando chaves estrangeiras para se relacionar com as entidades de origem. Enquanto isso, a relação Tem foi substituída pela adição, na tabela Música, de uma chave estrangeira para o ID de Álbum, além do atributo Faixa.

O tratamento e manipulação realizados para criação das tabelas são encontrados no arquivo Database_Creation.ipynb na seção Creating Dataframes r podem ser observados abaixo:
# Criação da tabela Ranking
df_table_chart = df_Charts_Songs[['ID_Chart', 'Código_Cidade', 'Type']].drop_duplicates().reset_index(drop = True)
df_table_chart.rename(columns={"ID_Chart": "ID",
"Type": "Tipo"}, inplace= True)
df_table_chart.head(3)
# Criação da tabela Cidades
df_table_cities = df_Cities[['Código_Cidade', 'Cidade', 'Estado']]
df_table_cities.head(4)
# Criação da tabela Estados
df_table_states = df_Cities[['Estado', 'Regiao']].drop_duplicates().reset_index(drop = True)
df_table_states.head(4)
# Criação da tabela Ranking-Músicas
df_table_chart_songs = df_Charts_Songs[['ID_Chart', 'Date', 'Song_id', 'Position']].reset_index(drop = True)
df_table_chart_songs.rename(columns={"ID_Chart": "ID_Ranking",
"Date": "Data",
"Song_id": "ID_Musica",
"Position": "Posição",}, inplace= True)
df_table_chart_songs.head(3)
# Criação da tabela Álbum-Músicas
df_table_songs = df_Charts_Songs[['Song_id', 'Album_id', 'Song_Name', 'Song_Explicit', 'Song_popularity',
'Song_danceability','Song_energy', 'Song_loudness',
'Song_valence', 'Song_track_number'
]].drop_duplicates().reset_index(drop = True)
df_table_songs.rename(columns={"Song_id": "ID",
"Album_id": "ID_Album",
"Song_Name": "Nome",
"Song_Explicit": "Explicita",
"Song_popularity": "Popularidade",
"Song_danceability": "Danceabilidade",
"Song_energy": "Energia",
"Song_loudness": "Volume",
"Song_valence": "Valencia",
"Song_track_number": "Faixa"}, inplace= True)
df_table_songs.head(4)
# Criação da tabela Álbum
df_table_albums = df_Charts_Songs[['Album_id', 'Album_name', 'Album_release',
'Album_image']].drop_duplicates().reset_index(drop = True)
df_table_albums.rename(columns={"Album_id": "ID",
"Album_name": "Nome",
"Album_release": "Data",
"Album_image": "Imagem_capa"}, inplace= True)
df_table_albums.head(4)
# Criação da tabela Artistas-Álbums
df_table_artist_albums = df_Charts_Songs[['Artist_id', 'Album_id']].drop_duplicates().reset_index(drop = True)
df_table_artist_albums.rename(columns={"Album_id": "ID_Album",
"Artist_id": "ID_Artista"}, inplace= True)
df_table_artist_albums.head(4)
# Criação da tabela Artistas
df_table_artists = df_Charts_Songs[['Artist_id', 'Artist_name', 'Artist_followers',
'Artist_popularity']].drop_duplicates("Artist_id").reset_index(drop = True)
df_table_artists.rename(columns={"Artist_id": "ID",
"Artist_name": "Nome",
"Artist_followers": "Seguidores",
"Artist_popularity": "Popularidade"}, inplace= True)
df_table_artists.head(4)
# Criação da tabela Artistas-imagens
artist_images = []
df_artistis_images = df_Charts_Songs[['Artist_id', 'Artist_images']].drop_duplicates().reset_index(drop = True)
for i in range(len(df_artistis_images)):
list_images = df_Charts_Songs["Artist_images"][i].replace("(", "").replace(")", "").replace("'", "").split(", ")
for image in list_images:
artist_images.append((df_artistis_images["Artist_id"][i], image))
df_table_artist_images = pd.DataFrame(artist_images, columns=['Artist_id', 'Image'])
df_table_artist_images.rename(columns={"Artist_id": "ID_Artista",
"Image": "Imagem",}, inplace= True)
df_table_artist_images.head(4)
# Criação da tabela Gêneros
artist_genders = []
df_artistis_genders = df_Charts_Songs[['Artist_id', 'Artist_genres']].drop_duplicates().reset_index(drop = True)
for i in range(len(df_artistis_genders)):
list_genders = df_Charts_Songs["Artist_genres"][i].replace("[", "").replace("]", "").replace("'", "").split(", ")
for gender in list_genders:
artist_genders.append((gender.replace(" ","_"), gender.title()))
df_table_genders = pd.DataFrame(artist_genders, columns=['Gender_id', 'Gender'])
df_table_genders.rename(columns={"Gender_id": "ID_Genero",
"Gender": "Genero",}, inplace= True)
df_table_genders = df_table_genders.drop_duplicates().reset_index(drop = True)
df_table_genders.head(4)
# Criação da tabela Artista-Gêneros
artist_genders = []
df_artistis_genders = df_Charts_Songs[['Artist_id', 'Artist_genres']].drop_duplicates().reset_index(drop = True)
for i in range(len(df_artistis_genders)):
list_genders = df_Charts_Songs["Artist_genres"][i].replace("[", "").replace("]", "").replace("'", "").split(", ")
for gender in list_genders:
artist_genders.append((df_artistis_genders["Artist_id"][i], gender.replace(" ","_")))
df_table_artist_genders = pd.DataFrame(artist_genders, columns=['Artist_id', 'Gender_id']).drop_duplicates().reset_index(drop = True)
df_table_artist_genders.rename(columns={"Artist_id": "ID_Artista",
"Gender": "Genero",}, inplace= True)
df_table_artist_genders.head(4)
Para a criação do banco de dados relacional deste trabalho foi utilizado o sistema de gerenciamento MySQL, que possui uma biblioteca para comunicação com Python. Para alimentar o banco de dados com as tabelas criadas pela modelagem relacional, foi utilizado o script “Database_Creation.py” em Python que utiliza a biblioteca “pymysql” para realizar a comunicação com o banco e a biblioteca pandas para ler os arquivos com os dados. Após tratamento dos dados (como, por exemplo, obter a imagem pelo link e depois convertê-la em binário, renomeação de atributos e exclusão de algumas colunas dispensadas), o banco é alimentado com os dataframes de cada tabela. A descrição de cada atributo selecionado para popular o banco de dados pode ser encontrada no dicionário de dados. A alimentação do banco de dados pode ser visto no arquivo Database_Creation.ipynb na seção Creating Tables.
Por último, foi criada uma aplicação Web simples para que o usuário possa realizar consultas à base criada. A aplicação foi desenvolvida utilizando a linguagem Python e SQL com as bibliotecas Flask e MySQL para o backend e as linguagens HTML, CSS e JavaScript para o front. O intuito da aplicação é recomendar músicas com base na entrada que o usuário der, além de possibilitar que o usuário visualize os rankings das músicas mais ouvidas por cidade, estado ou região brasileira. Todo o código da aplicação desenvolvida é encontrado na pasta Web Application.
A aplicação apresenta duas funcionalidades principais: a primeira é a recomendação de músicas, onde o usuário pode entrar com o nome completo ou parcial de um cantor, álbum, música ou cidade, sendo necessário escolher por qual parâmetro será realizada a recomendação, caso o termo buscado esteja presente na base na categoria selecionada - no caso positivo, são retornadas vinte músicas que o algoritmo ingênuo considerou mais semelhantes, comparando as propriedades volume, dançabilidade, energia e valência.
Na funcionalidade de recomendação, caso a entrada seja uma música, a aplicação busca as propriedades da faixa dada e os passa para o algoritmo que calcula a distância entre a música e todas as outras presentes na base, retornando as vinte com menor distância. Caso seja artista, álbum ou cidade, a aplicação busca por todas as faixas que apresentam o valor dado no tipo especificado, calcula a média de cada propriedade, para então passar essas médias como entrada para algoritmo. Então, se o usuário der um nome de um álbum por exemplo, primeiro serão resgatadas todas as músicas que pertencem ao álbum, depois é feito uma média das músicas para cada propriedade e essas médias que são passadas para o algoritmo que retornará as faixas com menores distâncias. A busca por artista tem um diferencial em que pode-se entrar com um ou dois artistas separados por “;”. Nesse caso, primeiro junta-se todas as músicas pertencentes aos artistas dados para então calcular-se a média.
Há ainda a possibilidade de uma busca personalizada para recomendação, onde o usuário pode especificar através de uma entrada por slider qual o nível de volume, dançabilidade, energia e valência que ele deseja nas músicas, onde a aplicação pega essas entradas, converte para parâmetros equivalentes às medidas das propriedades da música e os passa para o algoritmo. Sendo possível ainda nessa opção selecionar o critério das músicas não serem explícitas.
Já a segunda funcionalidade se resume em apresentar o ranking semanal das músicas mais populares por cidades brasileiras, estado ou região, sendo que o spotify, atualmente, só fornece esse ranking para as cidades: Belo Horizonte, Belém, Brasília, Campinas, Campo Grande, Cuiabá, Curitiba, Florianópolis, Fortaleza, Goiânia, Manaus, Porto Alegre, Recife, Rio de Janeiro, Salvador, São Paulo e Uberlândia. Há ainda a opção de visualizar o ranking “Local Pulse”.
Para os rankings das cidades, a aplicação apenas busca as músicas e suas respectivas posições para o tipo de ranking escolhido na cidade e semana especificadas, retornando suas informações incluindo a imagem da capa do álbum recuperada do banco de dados e um player fornecido pelo Spotify para se tocar um pedaço da música ou ela completa caso o usuário esteja logado no serviço no mesmo navegador.
Já para estado e região, como o Spotify Charts não fornece o número de reproduções de cada músicas, apenas suas posições, a aplicação busca os rankings das cidades pertencentes à localidade e faz um rankeamento personalizado, classificando de acordo com a quantidade de cidades em que a música entrou no ranking e as posições mais altas ocupadas nesses rankings para desempate.
Como a base de dados é bem pequena com relação ao número de músicas e o algoritmo para recomendação elaborado é bastante ingênuo, considerando ainda poucos parâmetros e condições, as recomendações não são assertivas no momento, mas conseguimos elaborar as funcionalidades que idealizamos e a aplicação pode vir a ser usada para futuras implementações e melhorias.
Para obtermos resultados das duas funcionalidades da nossa aplicação, recomendação e ranqueamentos, foram utilizadas diversas consultas ao banco de dados formado. Abaixo, são exibidas algumas:
Essa consulta seleciona as informações de - Danceabilidade, Energia, Valencia e Volume, presentes na tabela musica para determinada música informada pelo usuário na aplicação.
SELECT Danceabilidade, Energia, Valencia, Volume
FROM musica WHERE LOWER(musica.Nome) LIKE LOWER("{}");Essa consulta seleciona e obtém a média dos campos - Danceabilidade, Energia, Valencia e Volume, presentes na tabela musica para determinado álbum de entrada do usuário na aplicação. Como a informação de álbum não está presente na tabela de música, foi necessário realizar um join das duas tabelas, para obter as propriedades das músicas para o álbum selecionado pelo usuário.
SELECT AVG(Danceabilidade), AVG(Energia), AVG(Valencia), AVG(Volume)
FROM musica INNER JOIN album ON musica.ID_Album = album.ID
WHERE LOWER(album.Nome) LIKE LOWER("{}") GROUP BY album.ID;Essa consulta seleciona - musica.Nome, musica.ID, artista_albuns.Nome e Imagem_capa, presentes no join das tabelas de musica e artista_albuns, esta última foi criada anteriormente e foi composta de 2 joins entre outras 3 tabelas da base de dados. Essa seleção é feita quando ID da música estiver dentro da lista de músicas consultadas Todos os campos selecionados são renomeados e a consulta é ordenada pelo nome da música de forma crescente.
WITH artista_albuns AS ( SELECT album.ID AS ID_Album, artista.ID AS ID_artistas,
artista.Nome, Imagem_capa FROM album
INNER JOIN artista_albums ON album.ID = artista_albums.ID_Album
INNER JOIN artista ON artista_albums.ID_Artista = artista.ID)
SELECT musica.Nome AS MusicaNome, musica.ID AS ID,
artista_albuns.Nome AS ArtistaNome, Imagem_capa AS Imagem_capa FROM musica
LEFT OUTER JOIN artista_albuns ON musica.ID_Album = artista_albuns.ID_Album
WHERE musica.ID IN {id_songs} ORDER BY musica.Nome ASC;Essa consulta seleciona os campos - musica.Nome, musica.ID, artista_albuns.Nome e Imagem_capa, presentes no join das tabelas de musica, artista_albums e artista. Essa seleção é feita quando ID da música estiver dentro da lista de músicas consultadas. Todos os campos selecionados são renomeados.
SELECT musica.Nome AS MusicaNome, musica.ID AS ID, artista.Nome AS ArtistaNome,
Imagem_capa AS Imagem_capa
FROM musica INNER JOIN album ON musica.ID_Album = album.ID
INNER JOIN artista_albums ON album.ID = artista_albums.ID_Album
INNER JOIN artista ON artista_albums.ID_Artista = artista.ID
WHERE musica.ID IN {id_songs} ORDER BY musica.Nome ASCEssa consulta cria duas subconsultas antes de realizar a consulta final. A consulta final seleciona os campos - ID_songs.Posicao , musica.Nome, musica.ID, artista.Nome Imagem_capa e ID_songs.Data, obtidos através de joins realizados na subconsulta ID_songs e tabelas do próprio dataset, como musica, album, artista_albums e artista.
WITH
Rankig_Escolhido AS (SELECT ranking.ID, Data FROMranking
INNER JOIN cidade ON ranking.Codigo_Cidade = cidade.ID
INNER JOIN ranking_musicas ON ranking_musicas.ID_Ranking = ranking.ID
WHERE cidade.nome = "{cidade}" AND ranking.Tipo = "{tipo}"
ORDER BY DATA DESC LIMIT 1),
ID_songs AS (SELECT ID_musica, Posicao, ranking_musicas.Data
FROM Rankig_Escolhido
INNER JOIN ranking_musicas ON (ranking_musicas.Data = Rankig_Escolhido.data
AND ranking_musicas.ID_Ranking = Rankig_Escolhido.ID))
SELECT ID_songs.Posicao , musica.Nome AS MusicaNome, musica.ID AS ID, artista.Nome
AS ArtistaNome, Imagem_capa AS Imagem_capa, ID_songs.Data
FROM ID_songs
INNER JOIN musica ON musica.ID = ID_songs.ID_musica
INNER JOIN album ON musica.ID_Album = album.ID
INNER JOIN artista_albums ON album.ID = artista_albums.ID_Album
INNER JOIN artista ON artista_albums.ID_Artista = artista.ID
ORDER BY Posicao ASC;A consulta de união foi utilizada para funcionalidade de recomendação da aplicação, quando o usuário poderá entrar com o nome de até dois artistas. Então para isso, criamos duas subconsultas para obtermos as propriedades das músicas de cada um dos artistas. Sabemos que podíamos utilizar na cláusula WHERE a informação dos dois nomes de artista junto com o conectivo AND, mas optamos seguir dessa forma, para concluir a consulta exigida na definição do trabalho. Tendo as informações de músicas de cada um dos artistas, unimos as “tabelas” e depois consultamos desta “tabela” unida, que nomeamos de união, extraindo as informações de média para cada uma das propriedades .
WITH
Cantor_1 AS (SELECT Danceabilidade, Energia, Valencia, Volume
FROM musica INNER JOIN album ON musica.ID_Album = album.ID
INNER JOIN artista_albums ON album.ID = artista_albums.ID_Album
INNER JOIN artista ON artista_albums.ID_Artista = artista.ID
WHERE LOWER(artista.Nome) LIKE LOWER("{singer1}") GROUP BY artista.ID ),
Cantor_2 AS (SELECT Danceabilidade, Energia, Valencia, Volume
FROM musica INNER JOIN album ON musica.ID_Album = album.ID
INNER JOIN artista_albums ON album.ID = artista_albums.ID_Album
INNER JOIN artista ON artista_albums.ID_Artista = artista.ID
WHERE LOWER(artista.Nome) LIKE LOWER("{singer2}") GROUP BY artista.ID ),
uniao AS (SELECT * FROM Cantor_1 UNION ALL SELECT * FROM Cantor_2)
SELECT AVG(Danceabilidade) AS avg_Danceabilidade, AVG(Energia) AS avg_Energia,
AVG(Valencia) AS avg_Valencia, AVG(Volume) AS avg_Volume
FROM uniao;Essa consulta seleciona e obtém a média dos campos - Danceabilidade, Energia, Valencia e Volume, presentes na tabela musica, para determinado nome de artista que o usuário utiliza na aplicação. Como a informação de artista não está presente na tabela de música, foi necessário realizar 3 joins de 4 tabelas e agrupar pelo nome de artista, para obter as médias das propriedades das músicas para o artista selecionado pelo usuário.
SELECT AVG(Danceabilidade), AVG(Energia), AVG(Valencia),AVG(Volume)
FROM musica
INNER JOIN album ON musica.ID_Album = album.ID
INNER JOIN artista_albums ON album.ID = artista_albums.ID_Album
INNER JOIN artista ON artista_albums.ID_Artista = artista.ID
WHERE LOWER(artista.Nome) LIKE LOWER("{}") GROUP BYartista.ID ;Similar a consulta anterior, mas com o argumento de entrada do usuário a informação do nome da cidade.
SELECT AVG(Danceabilidade), AVG(Energia), AVG(Valencia),AVG(Volume)
FROM musica
INNER JOIN ranking_musicas ON musica.ID = ranking_musicas.ID_musica
INNER JOIN ranking ON ranking.ID = ranking_musicas.ID_Ranking
INNER JOIN cidade ON cidade.ID = ranking.Codigo_Cidade
WHERE LOWER(cidade.nome) LIKE LOWER("{}")
GROUP BY cidade.ID,;Essa consulta cria uma subconsulta antes de realizar a consulta final. A consulta final seleciona os campos - ID_songs.Posicao , musica.Nome, musica.ID, artista.Nome Imagem_capa e ID_songs.Data, obtidos através de joins realizados na subconsulta ID_songs e tabelas do próprio dataset, como musica, album, artista_albums e artista. Na subconsulta ID_songs é realizado um count total de linhas e pego o valor máximo da posição, criado uma classificação para cada uma das linhas através da função ROW_NUMBER, para aí sim ordenar por ID da música.
WITH
ID_songs AS(
SELECT ID_musica, COUNT(*), MAX(Posicao) , ranking_musicas.Data,
ROW_NUMBER() OVER (ORDER BY COUNT(*) DESC, MAX(Posicao) ASC) AS
Posicao
FROM ranking
INNER JOIN cidade ON ranking.Codigo_Cidade = cidade.ID
INNER JOIN estado ON estado.Nome = cidade.Estado
INNER JOIN ranking_musicas ON ranking_musicas.ID_Ranking = ranking.ID
WHERE ranking_musicas.Data = "{semana}"
AND estado.Regiao = "{cidade}" AND ranking.Tipo = "{tipo}"
GROUP BY ID_musica LIMIT 100)
SELECT ID_songs.Posicao , musica.Nome AS MusicaNome, musica.ID AS ID,
artista.Nome AS ArtistaNome, Imagem_capa AS Imagem_capa, ID_songs.Data
FROM ID_songs
INNER JOIN musica ON musica.ID = ID_songs.ID_musica
INNER JOIN album ON musica.ID_Album = album.ID
INNER JOIN artista_albums ON album.ID = artista_albums.ID_Album
INNER JOIN artista ON artista_albums.ID_Artista = artista.ID
GROUP BY ID ORDER BY Posicao ASC;Similar a consulta anterior, mas na subconsulta ID_songs é realizado somente uma seleção de colunas dos joins obtidos na consulta. Depois essa consulta é chamada na consulta final.
WITH ID_songs AS ( SELECT ID_musica, Posicao, ranking_musicas.Data FROM ranking
INNER JOIN cidade ON ranking.Codigo_Cidade = cidade.ID
INNER JOIN ranking_musicas ON ranking_musicas.ID_Ranking = ranking.ID
WHERE ranking_musicas.Data = "{semana}"
AND cidade.nome = "{cidade}" AND ranking.Tipo = "{tipo}")
SELECT ID_songs.Posicao , musica.Nome AS MusicaNome, musica.ID AS ID,
artista.Nome AS ArtistaNome, Imagem_capa AS Imagem_capa, ID_songs.Data
FROM ID_songs
INNER JOIN musica ON musica.ID = ID_songs.ID_musica
INNER JOIN album ON musica.ID_Album = album.ID
INNER JOIN artista_albums ON album.ID = artista_albums.ID_Album
INNER JOIN artista ON artista_albums.ID_Artista = artista.ID
ORDER BY Posicao ASC;É necessário ter o mysql instalado e executando, onde é recomendado criar uma virtual-env em python para instalar o projeto para que não haja o risco de conflitos entre as bibliotecas. O projeto foi feito em python3 e caso não o tenha instalado, é necessário instalá-lo antes de seguir para os próximos passos.
Com o python instalado, deve-se instalar as bibliotecas utilizadas especificadas no documento "requirements.txt", a instalação pode ser feita por:
$ pip3 install -r requirements.txt
Após isso é necessário mudar as configurações do arquivo config.yaml para seu nome de usuário e senha do mysql. O usuário geralmente é "root".
OBS: Se você estiver usando um hostou uma porta diferente do padrão, apenas adicione junto com os outros campos um campo host: "meu_novo_host"e port: XXXXsubstituindo os valores pelos seus.
Com os parâmetros certos preenchidos, primeiro deve-se executar o arquivo py que cria o banco de dados em seu servidor. Para isso execute o arquivo com "Database_creation.py" que pode ser executado rodando
$ python Database_Creation.py
na pasta do arquivo.
Com a base criada, basta apenas rodar o projeto com:
$ python app.py
A aplicação ficará então disponível no endereço endicado no cmd.
The MIT License (MIT) 2022 - Letícia Tavares. Leia o arquivo LICENSE.md para mais detalhes.
Spotify (2022) “Web API”, https://developer.spotify.com/documentation/web-api/, Março.
Spotify Charts (2022) “Spotify Charts”,https://spotifycharts.com/home/,Março.
IBGE (2022) “API de localidades”, https://servicodados.ibge.gov.br/api/docs/localidades,Março.

Neste projeto, iremos utilizar a linguagem Python aliada ao SQLite para construir um Date Warehouse para os Micrododados do ENADE dos anos de 2017, 2018 e 2019 e realizar uma análise de dados seguida de um modelo de predição.

Neste projeto, iremos utilizar a linguagem Python para realizar uma análise de dados seguida de um modelo de predição com base em dados de Seguro Saúde disponibilizados na plataforma Kaggle.

Estudo de caso de UX Design voltado para uma aplicação com foco em ajudar profissionais de TI a viverem menos ansiosos. Realizado por um time composto por Eduardo Leão, José Victor, Letícia Tavares e Luiz Eduardo.

Protótipo da aplicação com foco em ajudar profissionais de TI a viverem menos ansiosos desenvolvida no estudo de caso de UX Design realizado por um time composto por Eduardo Leão, José Victor, Letícia Tavares e Luiz Eduardo.


Construção de um método de classificação de preconceito em textos aplicado em frases retiradas da internet em português brasileiro, onde todas possuiam discurso de ódio.



